Last Week on My Mac: Secrets of Apple silicon
Next week’s anniversary is, of course, the fortieth of the Macintosh, launched in the famous 1984 commercial aired during the 1984 Super Bowl on 22 January, and shipped just two days later. Last week’s anniversary, though, was more sobering: the commissioning of the first computer, the Colossus, for code-breaking at Bletchley Park in England. That was so secret that Tommy Flowers, its designer, wasn’t recognised for his achievement until the 1970s, and details of his computers have only been emerging this century, long after his death in 1998.
Here I am wondering whether we’ll have to wait as long before the secrets inside Apple silicon chips are revealed.
After a few weeks hunting the legendary AMX matrix co-processor that has never even been referred to by Apple, a chance discovery of the implications of different instruction sets used by M1 and later chips has taken me to fine details reported by the command tool sysctl. Although Apple explains how to discover whether CPU cores in one of its chips support ARMv8.6-A features including bfloat16 arithmetic, its documentation carefully avoids giving any information away, and leaves developers to discover that for themselves.
As I’ll describe in more detail tomorrow, several curious anomalies appear when running virtual machines on Apple silicon. Using sysctl to check support for features introduced in the ARMv8.6-A instruction set, VMs running on M3 chips don’t appear to be able to support two of those: hw.optional.arm.FEAT_BF16 for bfloat16 support, and hw.optional.arm.FEAT_I8MM for advanced SIMD Int8 matrix multiplication instructions. But when you compare the performance of tests looking at unrelated features, some Accelerate library functions such as vDSP matrix multiplication using vDSP_mmul run unusually slowly in a VM compared to the host.
Apple describes vDSP_mmul as performing “an out-of-place multiplication of two matrices; single precision.” “This function multiplies an M-by-P matrix A by a P-by-N matrix B and stores the results in an M-by-N matrix C.” This is, therefore, well outside those functions added to ARMv8.6-A as “advanced SIMD Int8 matrix multiplication instructions”, or in Arm’s “General Matrix Multiply” group. In any case, vDSP_mmul is slowed just as much when run in a VM on an M1 host with ARMv8.5-A as it is on an M3 host and ARMv8.6-A.
Is it coincidence that that this same function call demonstrates an unusual pattern of core allocation?
This diagram shows how high-QoS threads are normally allocated to the cores of the first P cluster in an M1 Max CPU, until it’s fully loaded with four cores each running one thread. Only when a fifth thread is added does macOS allocate that to a core within the second P cluster, which it then fills until there are four threads running in each of its two P clusters. Note also how those threads, with their high QoS, are run on P cores as long as they’re available, leaving the Efficiency (E) cores to run background threads uninterrupted.
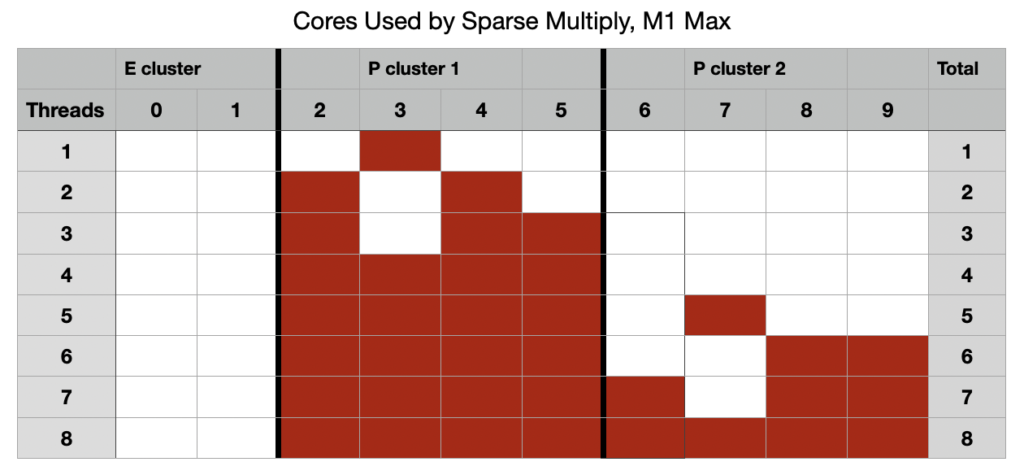
When running vDSP_mmul threads, but not with any other test, M1 Pro and Max chips, but not the M3 Pro, allocate their CPU cores in a completely different order, summarised in the diagram below.
Differences are obvious from two threads upwards, in that the second thread isn’t allocated to a second core in the first P cluster, but one in the second P cluster. Although being run at high QoS, the third thread is then allocated to the E cluster, and moved between its two cores. Core allocation is thus made to balance the load across the three clusters, with similar numbers of P cores running threads in each of the two clusters. Because these high QoS threads are also allocated to E cores, P cores are deliberately under-allocated. Although all 8 threads could have been run on P cores alone, because 2 of the threads are run on the E cores, there are 2 P cores sitting idle. macOS has chosen not to make most use of P cores when running high QoS threads, an exceptional allocation strategy.
One explanation of these observations is that, when possible, vDSP_mmul isn’t run on CPU cores at all, but on an out-of-core processor such as the AMX, which isn’t accessible to threads running in a VM, and isn’t a feature reported by sysctl.
I suppose we’ve only been using M1 chips for just over three years, which is very recent in terms of Tommy Flowers and his Colossus.