Are your text secrets safe in a PDF or image?
Sometimes, one person’s favourite feature is another’s threat. Live Text is a good example of this, and at the centre of this article. The text that you’re happy to extract from a photo using Live Text could, in other circumstances, only bring trouble.
Consider someone living in a country where the government has banned its opposition, and they had photos taken quite innocently of a protest with banners bearing anti-government slogans. Would they want their Mac to use Live Text to convert those slogans into text and store them in Spotlight’s indexes, for others to discover there?
When I last visited this subject a few months ago, one of my conclusions was that macOS Sonoma can analyse images using Live Text for text content and can classify objects within them, when allowed to by Siri & Spotlight settings. Once added to Spotlight’s indexes, Spotlight and its command tool mdfind can then find images whose metadata matches search terms. You may well have noticed this yourself when searching your Mac, when images of business cards or even photos and paintings have apparently been found on the basis of their Live Text content.
This time, rather than use popular file formats for photos like JPEG and HEIC, I used PNG and PDF, the latter because of its complexity and extensive use to contain text that often merits indexing and searching. I therefore laid out the distinctive search term syzygy999, as already used in the Spotlight features of my free utility Mints, in a document window, and took a screenshot saved in PNG format. I turned that into a single-page PDF using Preview (Sonoma 14.2.1), then ran OCR on a copy of that using PDF Expert. I placed those three files alongside those generated by Mints for its search test, and used both Mints and mdfind to see which of those files could be found in Spotlight searches.
Spotlight therefore had three different files to find:
PNG screenshot, which could recover the text on demand using Live Text;
PDF containing that screenshot, not itself containing the extracted text, but which could extract it using Live Text;
PDF containing the screenshot and its conversion to text, also extractable using Live Text.
Searching for the test text syzygy999 failed to discover it in any of those three files, whether performed by Mints or mdfind, although all the Mints test files were found correctly. I therefore rebuilt the Spotlight indexes on that volume, and once that was complete, tried again with the same result. I even left that Mac running overnight in the hope that a background process might result in the indexing of their text content. On further testing using mdfind, I discovered that tool could only find the third file when searching for syzygy or syzygy*, but not the correct string of syzygy999. Updating from Sonoma 14.2.1 to 14.3 didn’t change the results, nor did running these tests on another Mac with 14.3.
There is thus no evidence that content obtained by Live Text recognition on the first two test files was added to Spotlight indexes, contrary to experience with popular image file formats. Any recognisable text contained within PNG or PDF files, where text in the image hasn’t been converted into PDF content, isn’t searchable.
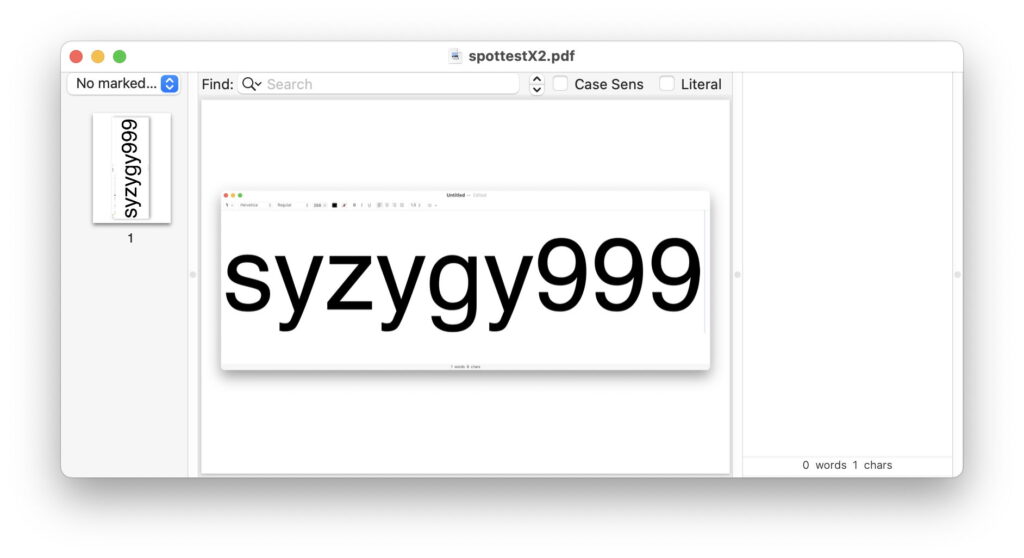
PDF files can contain text within images, text laid out in pages of the document, or both. When used to convert another graphics file format such as PNG to PDF, Preview can’t perform text recognition, so merely wraps the image into PDF format. Open that file using an app that can analyse its contents, such as Podofyllin, and all you can find is the image.
In the centre of this screenshot is the PDF file rendered by macOS, and at the right there is no corresponding text that has been extracted from the image. The only way to discover text here is to render the document and apply Live Text to that image.
Although Preview can’t perform text conversion, PDF Expert can, and writes that text to the document, where it’s displayed at the right. This makes it accessible to the Spotlight PDF metadata importer (mdimporter), so that it’s indexed and searchable. It’s not clear why, on this occasion, the whole word syzygy999 wasn’t indexed.
PDF documents generated directly from other file formats fare better with the PDF metadata importer, as shown in the extensive text at the right of one of the Mints test suite.
If you have PDF documents that have been assembled from scans or other images without undergoing any form of text recognition, then macOS currently can’t index any text that you may still be able to extract using Live Text. If you want to make the text content of a PDF document searchable, then you must ensure that it contains its own text content. On the other hand, if you’re worried that someone could search text content in your PNG images, or in images embedded in PDF documents, then this should be reassuring.
