APFS: How sparse files work
When sparse files were first introduced in APFS, they appeared to be unusual if not rare. Since then, changes in the way that macOS manages disk images and other improvements have made them more widespread. They’re now commonly found in:
many databases,
disk images, including standard UDRW read-write disk images,
most virtual machines.
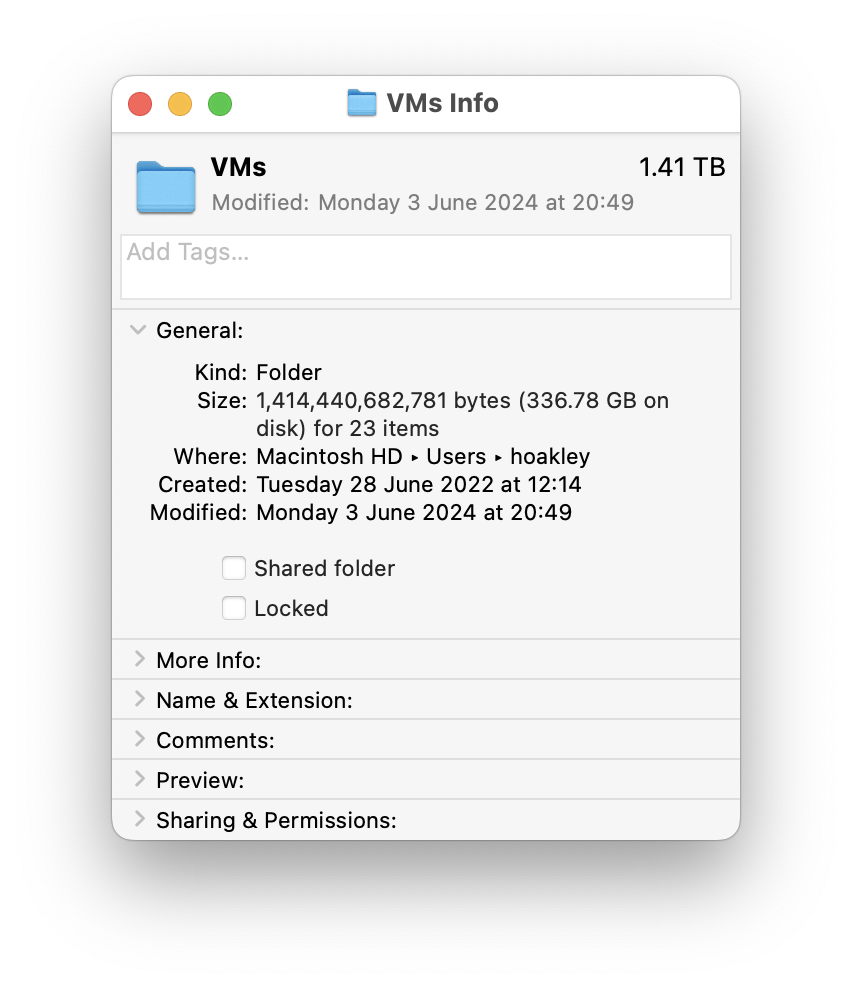
Because they’re transparent to the user, they’re easily overlooked. I recently opened Finder’s Get Info for a folder where I keep a small selection of virtual machines (VMs) for an Apple silicon Mac. Although their benefits are amplified here by the fact that some of those VMs have also been cloned, the nominal total size of that folder is 1.4 TB, although its contents only take 337 GB on disk, less than a quarter of their full size. That’s on an internal SSD of 2 TB with 1.4 TB free space. Without the storage efficiency of sparse files and clones, there would only be 360 GB of free space on that SSD.
Sparse files in APFS
Sparse files achieve their amazing economy by storing only the real data in a file consisting of substantial amounts of unused space. At their extreme, you can create a sparse file of 10 GB containing just a single block, 8 KB, of data, with the remainder unused. In regular format that file would require just over 10 GB of storage; in sparse format it takes just 8 KB on disk.
To achieve this, APFS does very little indeed. The file’s inode contains the INODE_IS_SPARSE flag, and in its extended-field the number of sparse bytes in the data stream, INO_EXT_TYPE_SPARSE_BYTES, is given as an unsigned 64-bit integer.
The trick is accomplished in the file’s extent map, which gives the offset in the file’s data in bytes, against the physical block address that the extent starts at. To return to the example 10 GB sparse file, its inode has the INODE_IS_SPARSE flag set, its extended-field gives the number of sparse bytes in the file, and its file extent map gives the physical block address for the non-null data at the offset at the end of the file. There’s no need for any additional metadata.
Writing a sparse file
For a file created by an app to be a sparse file, the following criteria must be met:
the file must be created using the FileHandle class for writing;
the nominal size of the file must exceed that contained in a single storage block, which determines the minimum size of a sparse file in any given APFS file system;
for the data to be stored in sparse format, voids (null data) within it must be created by seeking, rather than writing blocks of bytes such as 0x00.
This is straightforward using Swift or another appropriate language. First get the default FileManager
let fm = FileManager.default
Then create the new file at the URL url; this creates the inode in the file system
fm.createFile(atPath: url.path, contents: nil, attributes: nil)
Get a FileHandle object for writing to the file at that URL
let theFHandle = try FileHandle.init(forWritingTo: url)
Write the first block of non-null data to the start of the sparse file; this writes a block of data that’s recorded in the file extent map
theFHandle.write(data1)
To insert sparse data following that, seek to an offset in the file, at its end; this skips through the file to that new offset
theFHandle.seek(toFileOffset: offsetAtTheEnd)
Write a second block of data at the end; this block of data is also recorded in the file extent map
theFHandle.write(data2)
Close the FileHandle
theFHandle.closeFile()
At the end of this, the file has its INODE_IS_SPARSE flag, with INO_EXT_TYPE_SPARSE_BYTES recording the number of sparse bytes in the inode extended-field, and the file extent map records one storage block for the first block of data at the start of the file, and one for the second block of data at the end of the file.
Why sparse disk images?
Disk images often contain substantial amounts of free space that would be ideal for storage as a sparse file. Their creation is an ingenious combination of trimming free space inside the disk image, then saving the resulting file in sparse format.
When a UDRW disk image is first created, it’s written as a single file of the size set by the user. When that disk image is mounted for a second time, provided that its internal file system is HFS+ or APFS, it’s automatically trimmed so that all its unused blocks are coalesced into a single chunk of unused space. That doesn’t happen on its initial mount, because trimming is only triggered automatically when its file system is mounted, neither does it ever happen with internal FAT or ExFAT format disk images, for which trimming isn’t supported.
Once that trim has been performed, the disk image is then saved in sparse format, omitting the space occupied by its unused storage blocks.
Sparse files can readily explode
Because some methods of copying sparse files may not use FileHandle objects with calls that preserve their sparse format, they can inadvertently explode to their full size. When Time Machine backs up sparse files to APFS backup storage, their format is preserved, as it is when they’re restored to an APFS volume. Small changes may occur as a result of differences in block size reflected in file extents, though. I’m pleased to confirm that Carbon Copy Cloner also retains sparse file format in its backups and restores, and I suspect that SuperDuper! may well do so, although I haven’t tested that.
It’s easy to demonstrate what happens when copying doesn’t preserve the sparse format: create a sparse file, for example using Sparsity, and copy that across to another Mac using AirDrop. While the original will be seen to occupy far less space on disk that its nominal size, the copy on the other Mac will no longer be sparse, and what’s even worse copying the file takes the longer time expected for its nominal size, as it copies across all the null data.
In some circumstances, exploding sparse files can have serious consequences. Returning to the example of my folder of VMs, if I were to restore that from a backup that didn’t preserve all those sparse files, free space on that SSD would collapse from 1.4 TB to 360 GB.
Tools
Sparsity creates test sparse files and can discover which files in any given folder are in sparse format;
Precize provides full information about files, including whether they are sparse or clone files.