Inside M4 chips: Controlling frequency
To realise best performance and energy efficiency from the big.LITTLE architecture in Apple’s M-series chips requires careful management on the part of macOS. There’s much more to it than balancing loads over conventional multi-core CPUs with a single type of core, as each execution thread needs to be run in an optimal location. When deciding where to run a CPU thread, macOS controls:
which type of core, P or E, primarily determined by the thread’s Quality of Service (QoS), and core availability;
which cluster to run it in, for chips with more than one cluster of that type, set to try to keep as few clusters active as necessary;
which core within that cluster, determined by core availability, and semi-randomised to even out core use;
what frequency to run that cluster at, in turn depending on the core type and the thread’s QoS;
mobility of that thread between cores in the same cluster, and between clusters (when available).
Over the last four years, I have explored the rules apparently used for the first two, and the choice of frequency in E cores. This article looks in more detail at how the frequency of P clusters appears to be determined in M1, M3 and particularly M4 chips.
powermetrics provides more frequency figures than you know what to do with, although most are derived and to some extent imaginary, making reconciliation difficult. In tests reported in the previous article, I used those given as Cluster HW active frequency to demonstrate distinctive patterns seen on M4 P cores running different numbers of test threads.
This graph shows those frequencies for the active P cluster by the number of threads, for floating point, NEON and vDSP_mmul tests detailed previously. Frequencies for the first two tests are identical, at P core maximum for a single thread, then falling sharply from 2 to 3 threads. When more threads are run, a cluster that’s fully active is run at the same frequency as that for 5 threads (P cluster size on this M4 Pro), while the other P cluster follows the same frequencies shown in the graph for the number of threads it’s running.
To examine this further I first climbed a mountain.
Climbing a mountain
For this test I used three copies of my test app to run a total of three identical threads of my in-core floating point test code in a mountain pattern. I first started powermetrics gathering data, then launched the first thread, followed by the second, and then the third. My objective was to observe an initial period when just one test thread was running, a second with the second test thread in addition, a third when all three threads would be running, and then watch the sequence reverse as each thread ended. This is shown in the results below.
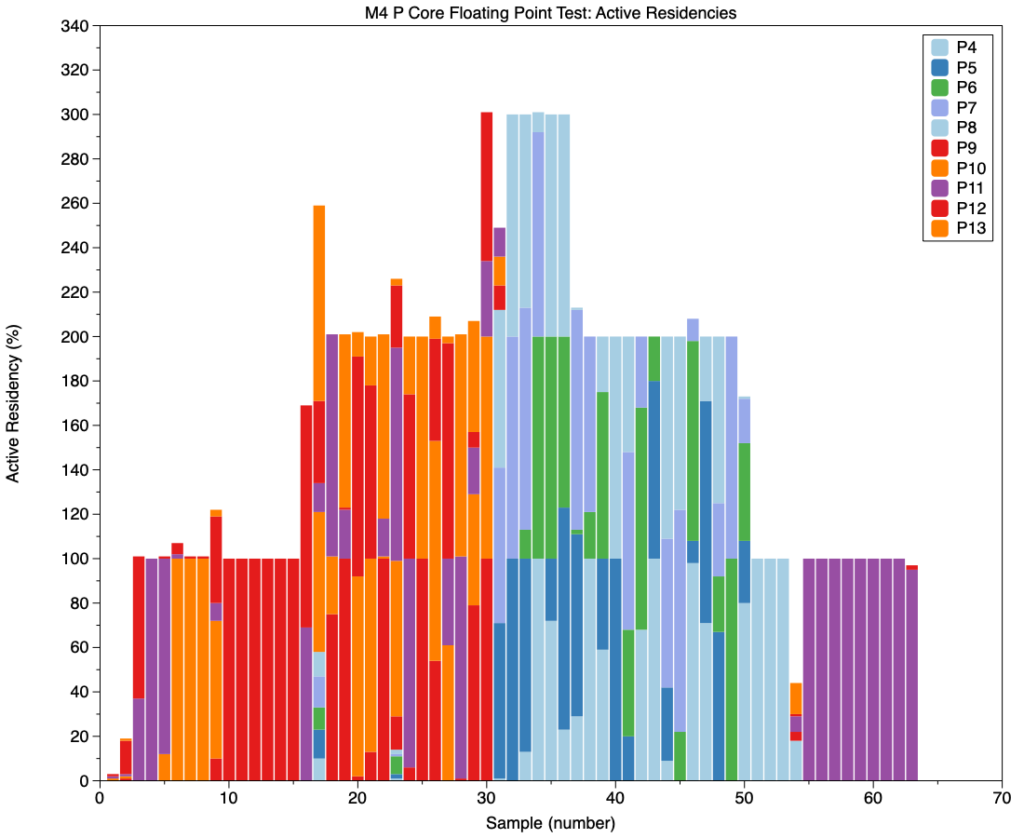
This chart shows active residencies by core and cluster for the P cores in an M4 Pro, with 5 P cores in each of its two P clusters, during this test. For the first 15 sample periods (1.5 seconds), a single test thread is moved around between cores in the second P cluster (P1). That’s joined by the second thread run on another core in the same cluster, until sample 30, when the third thread is added, pushing the total active residency to 300%.
At that point, all three threads are moved to three cores in the first P cluster (P0), whose bars are shown in blues and green. The first thread completes in sample 37, leaving two threads with 200% active residency to continue in that cluster until sample 50, when the second thread completes, leaving just one running. In sample 54 (5.4 seconds after test start), that one remaining thread is moved back to complete on core P11 in the second cluster late in sample 63.
In that period of 6.3 seconds, each of the two P clusters has run 1, 2 and 3 threads.
This graph shows cluster frequencies over the same period, this time given in seconds elapsed rather than sample number. The red line and points show the frequency of cluster P1, and blue for P0. Those undergo step changes when each cluster is running test threads. The inactive cluster is normally shut down with a frequency of 0 MHz, although there are some brief spikes from that as well.
Combining active residency bars in yellow with core frequency lines, it’s clear that cluster frequency is close to core maximum at 4,500 MHz when only a single thread is running. With two threads, it’s reduced to 4,400 MHz, and down to 3,900 MHz when all three threads are running. Those changes are symmetrical for loading and unloading clusters, and shown no signs of hysteresis (different values during loading and unloading).
Closer examination gives frequencies of 4,511 MHz at 100% active residency, 4,415 MHz at 200%, and 3,924 MHz at 300%e. The latter is 87% of maximum frequency, a large enough reduction to be reflected in performance. Essentially identical figures are found for NEON tests as well as these for floating point.
Although this test method can give highly reproducible results, the floating point and NEON tests used don’t resemble threads seen in everyday use. The next step is to extend that by looking at thread numbers and frequency when running more normal code.
Compressing a file
Fortunately, I have already built a suitable platform for real-world testing in a one-trick pony named Cormorant, a basic compression-decompression utility using Apple Archive. Although not a patch on serious apps like Keka, Cormorant can set the number and QoS of threads to be run during compression/decompression. Because it relies on Apple’s framework, it actually runs more than just the threads set in its controls, but still provides a way to control active residency. I therefore ran a test compression (15.5 GB IPSW image file) at maximum QoS to ensure it’s dispatched to P cores, and 1-3 threads.
Time taken to compress the test file changes greatly according to the number of threads used:
1 thread takes 49.6 s, at 313 MB/s;
2 threads takes 26.8 s, at 578 MB/s, 191% of the throughput of the single thread;
3 threads takes 18.7 s, at 829 MB/s, 265% of the single thread.
These appear to follow the pattern of frequencies observed on my in-core tests.
This chart shows the opening 3 seconds of single-thread compression, with cluster frequency in the points and line, and total active residency multiplied by 10 (to scale to a common y axis) in pale blue bars. Two significant periods are shown: in samples 12-21, active residency is high, between 300-430%, and frequency is lower at around 4,000 MHz. Following that, active residency falls to about 200% and frequency rises to 4,200 MHz.
Because active residency was so variable in these tests, I pooled paired values for that and cluster frequency, gathered over 3 second periods, and plotted those.
Although at active residencies below about 180% there’s a wide scatter, above that there’s a good linear regression, showing steady decline in frequency over active residencies ranging from 180% to 450%.
The following two graphs show equivalents for tests using 2 and 3 threads. The first of those has two outliers at total active residencies above 490%, corresponding to unusual conditions during the test. I have therefore excluded those from subsequent analyses.
The last step is to pool paired results from all three test conditions, and arrive at a line of best fit.
Between total cluster residencies of 150-500%, this works best with a quadratic curve with the equation
F = 4630.05 – (2.0899 x R) + (0.0010107 x R^2)
from which a different relationship is predicted between F, frequency in MHz, and R, total active residency in %.
My other real-world test makes use of the fact that, when virtualising macOS, the number of virtual cores on the host is specified.
Hosting virtual cores
Although virtualisation relies on frameworks run on the host, experience is that its demand on host P cores is constrained to the number of virtual cores allocated, with each of those resulting in 100% active residency, equating to the whole of a P core on the host. powermetrics started collecting sample periods immediately before a macOS 14 VM was launched, and the first 3 seconds (30 samples) were collected and analysed for VMs with 1-3 virtual cores.
This shows the first of those, a VM allocated just a single virtual core, with cluster frequencies shown as red and blue lines, and total active residency multiplied by 10 in the pale blue bars. With a steady total active residency of 100%, active cluster frequency was about 4,500 MHz. Note that sample 7 included transfer of the threads from P1 to P0 in a sharp peak to a total active residency of over 500%.
Average frequencies can thus be calculated for each of the three tests, at 100-300% active residencies.
Set frequencies
I now have estimates of cluster frequencies for cluster total active residencies from:
in-core tests using floating point
in-core tests using NEON
compression
virtualisation
against which I compare a matrix multiplication test that may be run on shared matrix co-processors (AMX). These are shown in the table below.
Running a single thread in a cluster should result in a total active residency of 100%, for which macOS sets the cluster frequency at P core maximum, of 4,400-4,511 MHz. That for 200% is lower, at between 4,000-4,400 MHz, and falls off further to about 3,800 when all 5 cores are at 100% active residency. Frequencies set for the vDSP_mmul test are significantly lower throughout, supporting the proposal that test isn’t being run conventionally in P cores, but in a co-processor.
A sixth thread would then be loaded onto the other P cluster, where cluster frequency would be set at P core maximum again, progressively reducing with additional threads until that cluster was also running at about 3,800 MHz.
Following this, I returned to the tests I have performed over the last four years on M1 and M3 P cores. Although I haven’t analysed those formally, I now believe that their frequencies are controlled by macOS as follows:
M1 1 core at 3,228 MHz, 2 cores 3,132 MHz, 3-6 cores 3,036 MHz.
M3 1 core at 3,624 MHz (below maximum of 4,056), 2-6 cores 3,576 MHz.
The range of frequencies in the M1 and M3 is narrower, resulting in less difference in performance between single- and multi-core tests. However, the M4 falls to 87% maximum frequency at 3 threads and more, which is substantial. It’s worth noting that Geekbench single-core results for the M4 are around 3,892 and would scale up to a multi-core result of 38,920 on an M4 Pro with 10 P cores, whereas the actual multi-core score is about 22,700, 58% of the scaled value. Although the effects of lower frequency can’t account for all that difference, they must surely contribute to it.
Why?
Two plausible contenders for the reason that macOS reduces P cluster frequency with increasing active residency are for thermal management, hence reliability, and when competing for a limited resource, perhaps the L2 cache shared within each cluster.
Reductions in cluster frequency seen here isn’t thermal throttling, though. Tests were intentionally kept brief in order to accommodate their results in reasonably short series of powermetrics results. Power use was highest in the NEON and vDSP_mmul tests, and lowest in floating point, although there don’t appear to be matching differences in frequency control. As noted in the previous tests, High Power mode didn’t alter frequency control, although frequencies were reduced in Low Power mode.
It’s most likely that this frequency regulation is pre-emptive, and based not just on CPU cores, but allows for likely heat output in the rest of the Mac.
Key information
When running on Apple silicon Macs, macOS modulates ‘cluster HW active frequency’ of P cores, limiting frequency to below maximum when cluster total active residency exceeds 100%.
Although small in M1 variants, this is most prominent in M4 variants, where a total active residency of 300% may reduce cluster frequency to 87% of maximum.
Frequency limitation is most probably part of a pre-emptive strategy in thermal management.
Frequency limitation is at least partly responsible for non-linear changes in performance with increasing recruitment of P cores, as illustrated in single- and multi-core benchmarks.
Control of P cores by macOS is complex, particularly in M4 variants.
Previous articles
Inside M4 chips: P cores
Inside M4 chips: P cores hosting a VM
Inside M4 chips: E and P cores
Inside M4 chips: CPU core performance
Inside M4 chips: CPU power, energy and mystery
Inside M4 chips: Matrix processing and Power Modes
Explainer
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.
Acknowledgements
Several of you have contributed to discussions here, but Maynard Handley has for several years provided sage advice, challenging discussion, and his personal mine of information. Thank you all.




