A brief history of text on the Mac
When the Mac 128K was launched, the computing world was quite happy working with text composed using single-byte characters, and the full 256 characters of Extended ASCII seemed quite sufficient. In those days, encoding text for each language was based on its code page, a different set of 256 characters according to that language’s needs and conventions.
The Mac’s initial version of Extended ASCII became its standard Mac OS Roman encoding by System 6.0.4 in 1989. Since then it has been modified to add support for the euro currency symbol in 1998, and is still supported in macOS. Other code pages for single-byte character encoding extended to Mac OS Icelandic, for example, which formed the basis of Macintosh Latin used by the popular Kermit file-transfer software.
Many languages can’t be encoded in such small character sets, and required 2-byte encodings instead. Dealing with these complexities and support for different writing directions became the task of the Script Manager, introduced in System 4.1 in 1987.
Another fundamental concept in Mac OS has been that text isn’t just a character set, but has to be drawn on the display with other graphics content. Text handling thus became integrated with its rendering and features such as word breaking and ligatures. Support for handling text using mixed scripts came in two optional extensions: WorldScript I for single-byte encodings, and WorldScript II for 2-byte encodings such as Chinese, Japanese and Korean.
There were two more mundane complications for the Classic Mac OS user: line termination, and string handling in code.
While MS-DOS and PCs used the combination of carriage return and line feed characters (rn) to terminate lines, Mac OS followed the Unix convention of using line feed (n) alone. Although the better text editors supported both, and would convert text files between them, that became tedious.
Much application development for Classic Mac OS was performed in Apple’s Macintosh Programmer’s Workshop (MPW) using the extended implementation of Pascal known as Object Pascal. This had adopted UCSD Pascal string format, in which the first byte(s) in its native strings contained the length of the string in bytes, rather than its first character. This was all the more confusing when combining projects with C, whose native string format didn’t preface its characters with length, but terminated every string with a null byte.
In 1985, while working on KanjiTalk, the heart of the Mac’s Japanese localisation, Mark Davis and Ken Krugler developed ideas that eventually led to Unicode. When Davis hired Lee Collins to join him at Apple from Xerox, they developed their proposals further, and in 1987 Apple was one of the founders of the Unicode Consortium. The following year, Apple decided to build Unicode support into TrueType, the new font standard it released in System 7 in 1991.
In 1998 System 8.5 integrated support for Unicode text, in Apple Type Services for Unicode Imaging, ATSUI, which was still supported until 2022, and has finally been removed altogether in macOS 14 Sonoma the following year. Initial support for Unicode included UTF-16 encoding to the Unicode Standard version 2.1. Conversion between text encodings was provided by the Text Encoding Conversion Manager.
Core Text superseded ATSUI in Mac OS X 10.5 Leopard in 2007, and is part of the Cocoa text system inherited from NeXTSTEP.
One unexpected new feature of Unicode was the LastResort, the symbol shown for a code point that doesn’t exist yet, and the product of garbled text, seen here in 2007.
Even in familiar languages like Greek, Unicode offers exotics such as GREEK CAPITAL LETTER ALPHA WITH DASIA AND PERISPOMENI AND PROSGEGRAMMENI, whatever that might be used for.
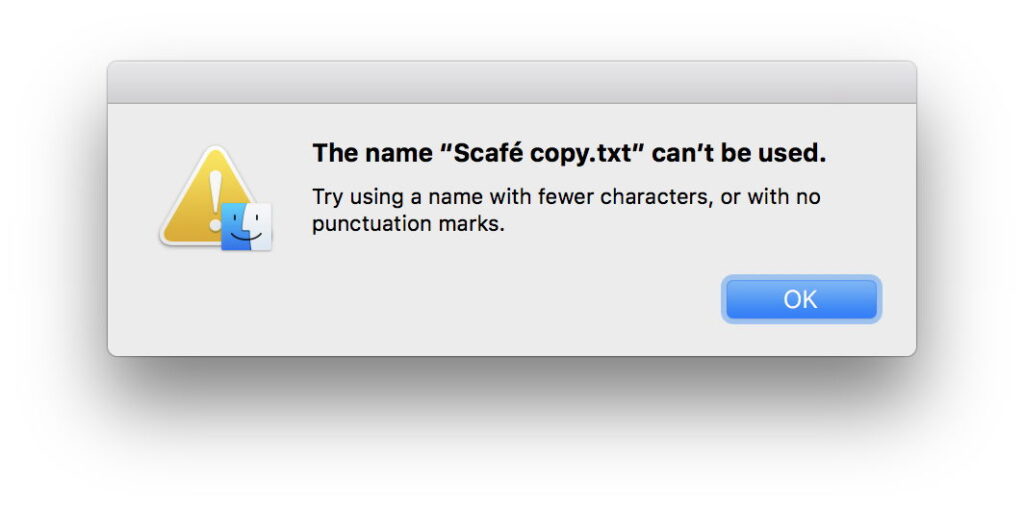
However, Unicode has brought its own problems, among them its acceptance of multiple code points (character encodings) for visually identical characters. In normal text use this can impede searching, but becomes more critical with the naming of files and directories.
The letter Å can be represented in UTF-8 as either C3 85 (Form C) or 41 CC 8A (Form D). Search for the word Ångström using Form C, and you won’t find the same word using Form D instead. A file system that allows both forms to appear independently in file and directory names appears to the user to allow items with duplicate names, and that poses further problems for search.
In Apple’s Macintosh Extended (HFS+) file system, Unicode normalisation is used to map characters to Unicode Form D, but when Apple developed APFS it intended to leave any normalisation to apps. Early releases of APFS thus didn’t perform normalisation, resulting in many problems for app developers and users. This was rectified by incorporating a normalisation layer into macOS to return to the relative sanity of Form D.
It would perhaps be better to close without mentioning the annual additions to emoji supported in Unicode, as announced prominently in macOS updates. It has been a long and sometimes arduous journey from Extended ASCII to the of .
Apple Inside Macintosh: Text (1993)
Pascal string types in the Free Pascal and Lazarus Wiki
Unicode – the beginnings, Mark Davis and others
Apple Core Text Programming Guide (2007-2014)
Apple Core Text, current documentation



{kind=link}
{kind=link}