Inside M4 chips: CPU core management
Whether you’re a developer or user, gaining an understanding of how macOS manages the cores in an Apple silicon CPU is important. It explains what you will see in action when you open Activity Monitor, how your apps get to deliver optimal performance, and why you can’t speed up background tasks like Time Machine backups. In this series (links below) I’ve been trying to piece this together for the M4 family, and this article is my first attempt to summarise as much of the story as I know so far. I therefore welcome your comments, counter-arguments and improvements.
Scope
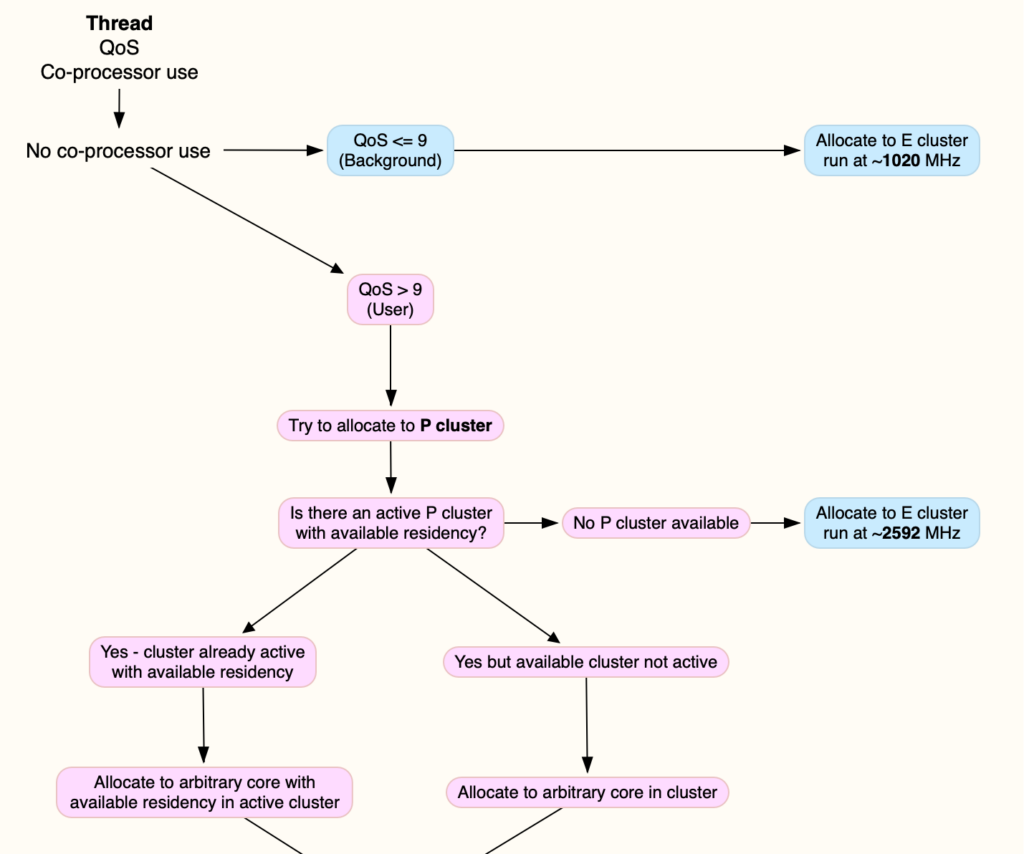
For the purposes of this article, I’ll consider a single thread that macOS is ready to load onto a CPU core for execution. For that to happen, five decisions are to be made:
which type of core, P or E,
which cluster to run it in,
which core within that cluster,
what frequency to run that cluster at,
the mobility of that thread between cores in the same cluster, and between clusters (when available).
Which type of core?
Since the early days of analysing M1 CPUs, it has been clear that the choice between P and E core types is made on the Quality of Service (QoS) assigned to the thread, availability of a core of that type, and whether the thread uses a co-processor such as the AMX. For the sake of generality and simplicity, I’ll here ignore the last of those, and consider only threads that are executed by the CPU alone.
QoS is primarily set by the process owning that thread, in the setting exposed to the programmer and user, although internally QoS is modulated by other factors including thermal environment. Threads assigned a QoS of 9 or less, designated Background, are allocated exclusively to E cores, while those with higher QoS of ‘user’ levels are preferentially allocated to P cores. When those are unavailable, they may be allocated to E cores instead.
This can be changed on the fly, reassigning higher QoS threads to run on E cores, but that’s not currently possible the other way around, so low QoS threads can’t be run on P cores. The sole exception to that is when run inside a virtual machine, when VM virtual cores are given high QoS, allowing low QoS threads within the VM to benefit from the speed of P cores.
Which cluster?
M4 Pro and Max variants have two clusters of P cores, so the next decision is which of those to run a higher QoS thread on:
if both clusters are shut down, one will be chosen and its frequency brought up;
if one cluster is already running and has sufficient idle residency (‘available residency’) to accommodate the thread, that will be chosen;
if one cluster already has full active residency, the other cluster will be chosen;
if both clusters already have full active residency, then the thread will be allocated to the E cluster instead.
This fills an active P cluster before allocating threads to the inactive one, and fills both P clusters before allocating a higher QoS thread to the E cluster.
Cluster allocation is of course simpler on the base M4, where there’s only one E and one P cluster. Should Apple make an M4 Ultra as expected, then that would not only have four P clusters, but two E clusters. Until that happens, we can only speculate that similar would then apply, including the E clusters.
Which core within the cluster?
This is perhaps the simplest decision to make. If there’s only one core with available residency in that cluster, that’s the only choice. Otherwise macOS picks an arbitrary core from those available, apparently to ensure roughly even use of cores within each cluster.
What frequency?
For the E cluster, choice of frequency appears straightforward, with low QoS threads being run at minimum E core frequency of 1,020 MHz or slightly higher, and higher QoS threads spilt over from fully occupied P clusters are run at E core maximum frequency of 2,592 MHz.
P cluster frequency appears to be determined by the total active residency of that cluster after the new thread has been added. When that’s the only thread running in that cluster, maximum frequency of 4,512 MHz is chosen, but rising total active residency reduces that in steps down to about 3,852 MHz when all the cores in the cluster are at 100% active residency. In most cases, the big reduction in frequency occurs when going from about 200% to 300% total active residency. This currently appears to be part of a strategy to pre-emptively minimise the risk of thermal stress within the chip.
Thread mobility
Once the thread has been loaded into a core in the optimal cluster running at the chosen frequency, it’s likely to be moved periodically, both to any other free core within that cluster, and to another cluster, when available. While this does occur in previous M-series CPUs, it appears particularly prominent in M4 variants.
Movement of threads within a cluster can occur quite frequently, every 0.1 second or so, particularly within the E cluster. Movement between clusters occurs less frequently, about every 4-5 seconds, and would only occur when the other cluster is shut down or idle, so free to run all the threads of the current cluster. This is most probably to ensure even thermal conditions within the chip.
Summary
The whole strategy is shown in the following diagram, also available as a tear-out PDF from here: m4coremanagement1
Previous articles
Inside M4 chips: P cores
Inside M4 chips: P cores hosting a VM
Inside M4 chips: E and P cores
Inside M4 chips: CPU core performance
Inside M4 chips: CPU power, energy and mystery
Inside M4 chips: Matrix processing and Power Modes
Inside M4 chips: Controlling frequency
Explainer
Residency is the percentage of time a core is in a specific state. Idle residency is thus the percentage of time that core is idle and not processing instructions. Active residency is the percentage of time it isn’t idle, but is actively processing instructions. Down residency is the percentage of time the core is shut down. All these are independent of the core’s frequency or clock speed.




