Tune for Performance: do more threads run faster?
One of the most distinctive features about modern Macs is that they have multiple cores, in Apple silicon models a minimum of eight. For an app to be able to make use of more than one core (or its equivalent) at a time it needs to divide its processing into threads, discrete blocks of code that can be run on different cores by macOS. If it doesn’t do that, then running that app on a high-end Pro, Max or Ultra chip is unlikely to be significantly faster than on a base model (assuming that task is CPU-bound).
Activity Monitor
You might be able to get a good idea as to how well an app makes use of multiple cores from watching it in use in Activity Monitor’s CPU History window, but in many cases that isn’t conclusive, and needs to be confirmed.
To illustrate ways to tackle this, I take the example of file compression. Some methods lend themselves to multiple threads better than others, and some may be implemented in a way that won’t accelerate when several cores are available. For the occasional user this might make little difference, but if you were to spend much of your day waiting for 10-100 GB files to compress, it merits a little exploration.
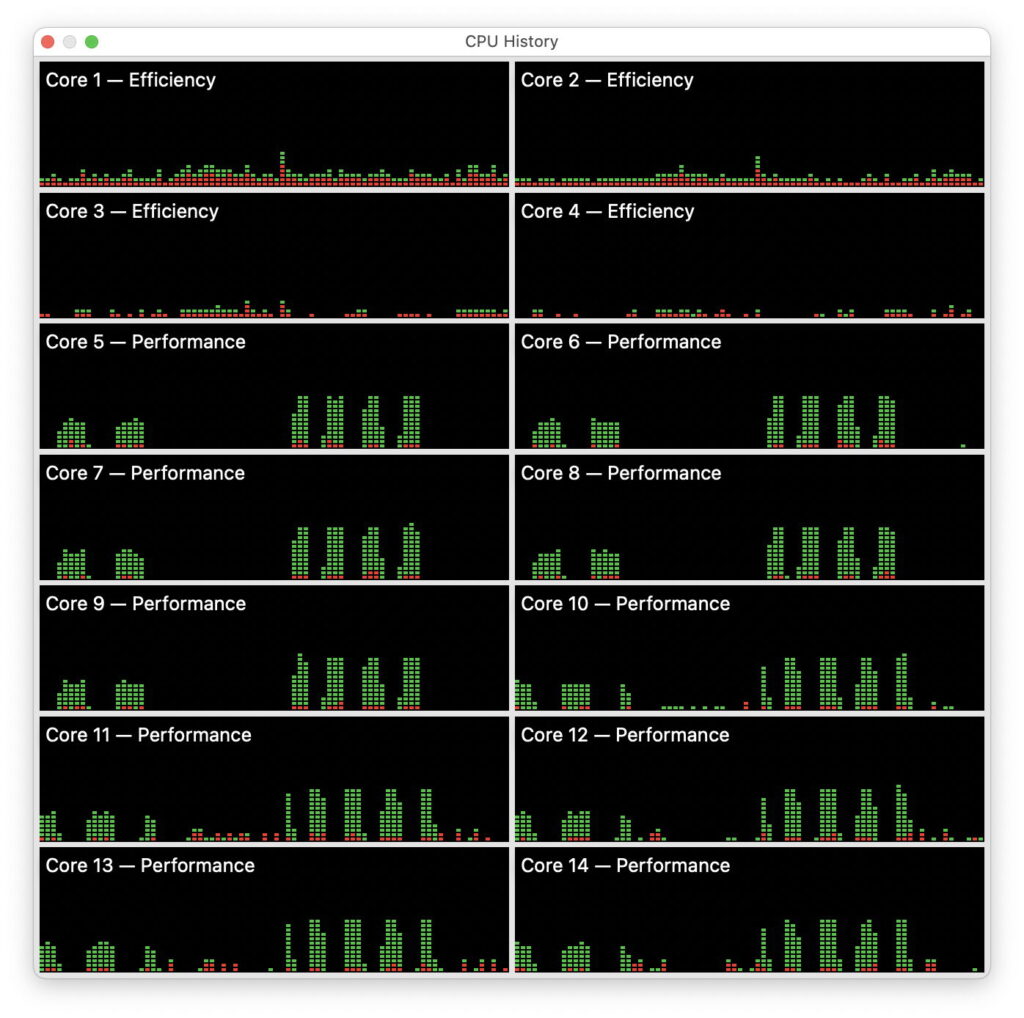
This CPU History window from a compression task run on an M4 Pro is typically unhelpful. A single file compression is seen in the group of 4-5 peaks in CPU in the right half of each trace. Although compression used all ten P cores, it appears to have been moved between P clusters, seen by comparing the timing of peaks on Cores 8 and 10, 9 and 11. At no time does the task appear to exceed 50% active residency on any of the cores, though. All you can do is guess as to what might be going on, and whether it might run faster on twelve or more P cores.
On another run, the same task is reported to have reached a peak of 500% CPU in 12 threads, but would it exceed that on more P cores, given that 10 were available?
Timing performance
As usual, I’ve been cheating a little to generate those results, by using my simple compression-decompression app Cormorant, in which I control how many threads it uses. If the app you’re trying to investigate offers a similar feature, then you can set up a standard task, here the compression of a 15.517 GB IPSW file, and time how long it takes using different numbers of threads.
The answers from Cormorant, which conveniently performs its own timing, are:
1 thread takes 49.32 seconds
2 take 26.74 s
3 take 18.60 s
4 take 14.29 s
5 take 11.21 s.
So Cormorant’s compression can make good use of more P cores, although with diminishing returns.
Very few apps give you this level of control, though. The only other compression utility that does appear to is Keka.
In its settings, you can give its tasks a maximum number of threads, and even run them at custom Quality of Service (QoS) if you want them to be run in the background on E cores, and not interrupt your work on P cores.
Controlling threads
There is one way that you can limit the effective number of threads used by an arbitrary app, and that’s to run it in a Virtual Machine, as you control the number of virtual cores that it uses. While you can just about run a macOS VM on a single core alone, I suggest that a more workable starting point is two cores, and you can increase that number up to the total of P cores in the host without causing problems.
VMs have other virtues, including their relative lack of background processes, allowing their virtual cores to be almost entirely devoted to your test task. However, as they can’t run apps from the App Store other than Apple’s free suite of Pages, Numbers and Keynote, that could prevent you from using them for testing.
To set up a VM for thread tests, I duplicated a standard Sonoma 14.7.1 VM so I could throw it away at the end, opened it with five virtual cores, and copied over the test app Cormorant and file. I then closed that VM down, set it to use 2 virtual cores, opened it and ran my test. I repeated that with an increasing number of virtual cores up to a total of 5. Compression times are:
2 vCPUs take 30.13 seconds
3 take 21.36 s
4 take 17.18 s
5 take 13.59 s.
Those are only slightly slower than their equivalents from the host tests above.
Analysis
Plotting those results out using DataGraph, the lines of best fit follow power laws:
for real cores, time = 49.8863/(T^0.91169)
for virtual cores, time = 54.737/(T^0.854318)
where T is the number of threads. That explains the apparently diminishing returns with increasing numbers of threads, although the maths isn’t as simple as we might like.
A better way to look at this is by calculating the rate of compression in GB/s, simply by dividing the file size of 15.517 GB by each time. Here we end up with straight lines from linear regression, that are more amenable to thought.
Those regressions are:
for real cores, rate of compression = 0.0464 + (0.264 x T)
for virtual cores, rate of compression = 0.102 + (0.206 x T)
which are more generally useful.
Tuning performance
This might appear over-elaborate and of little practical use, but we now have a much better understanding of the factors limiting compression performance:
The more threads compression uses, the shorter time a task will take.
There are limits to that improvement, though, when substantially more than 5 threads are used.
Compression rates achieved in M4 P cores are significantly lower than read or write speeds of the internal SSD, so aren’t likely to be limited by the speed of a faster SSD (TB3 or USB4).
As compression appears to be CPU-bound, faster P cores would also be expected to result in shorter times.
Improving the efficiency of the compression code could increase performance.
Compression in a VM runs at about 78% of speed on the host.
To see how reliable these are, I therefore repeated the Cormorant test using all 10 P cores on the host Mac, which took 6.80 seconds, a little more than half the time for 5 cores. That’s a compression rate of 2.28 GB/s, rather less than the 2.69 GB/s predicted by the linear regression. That’s now approaching the write speed of some TB3 SSDs, and the rate-limiting step could then change to be the write performance of the storage being used, rather than CPU cores.




