Friday magic: how to cheat on E cores and get free performance
I’d love to be able to bring you a Mac magic trick every Friday, but they aren’t so easy to discover. Today’s is mainly for those with Apple silicon Macs, and is all about gaming the way that macOS allocates threads to their cores. Here, I’ll show you how to more than double the performance of the E cores at no cost to the P cores.
To do this, I’m using my test app AsmAttic to run two different types of core-intensive threads, one performing floating point maths including a fused multiply-add operation, the other running the NEON vector processor flat out.
When I run a single NEON thread of a billion loops at low Quality of Service (QoS) so that it’s run on the E cores, it takes 2.61 seconds to complete, instead of the 0.60 seconds it takes on a P core. But how can I get that same thread, running on the E cluster, to complete in only 1.03 seconds, 40% of the time it should take, and closer to the performance of a P core?
The answer is to run 11 more threads of 3 billion loops of floating point at the same time. That might seem paradoxical, particularly when those additional threads perform the same with or without that NEON thread on the E cores, so come for free. Perhaps I’d better explain what’s going on here.
Normally, when you run these threads at low QoS, macOS runs them on the E cores, at low frequency for added efficiency. On the M4 Pro used for these tests, the NEON test that took 2.61 seconds was on E cores pottering along at a frequency of less than 1,100 MHz across the whole of the E cluster, not much faster than their idle frequency of 1,020 MHz.
One way to get macOS to increase the frequency of all the E cores in the cluster is to persuade it to run a thread with high QoS that won’t fit onto the P cores. In this M4 Pro, that means loading its CPU with 11 floating point threads, of which 10 will be run on the two clusters of 5 P cores each. That leaves the eleventh thread to go on the E cluster. macOS then kindly increases the frequency of the E cluster to around 2,592 MHz, giving my NEON thread a speed boost of around 235%, which accounts for the performance increase I observed.
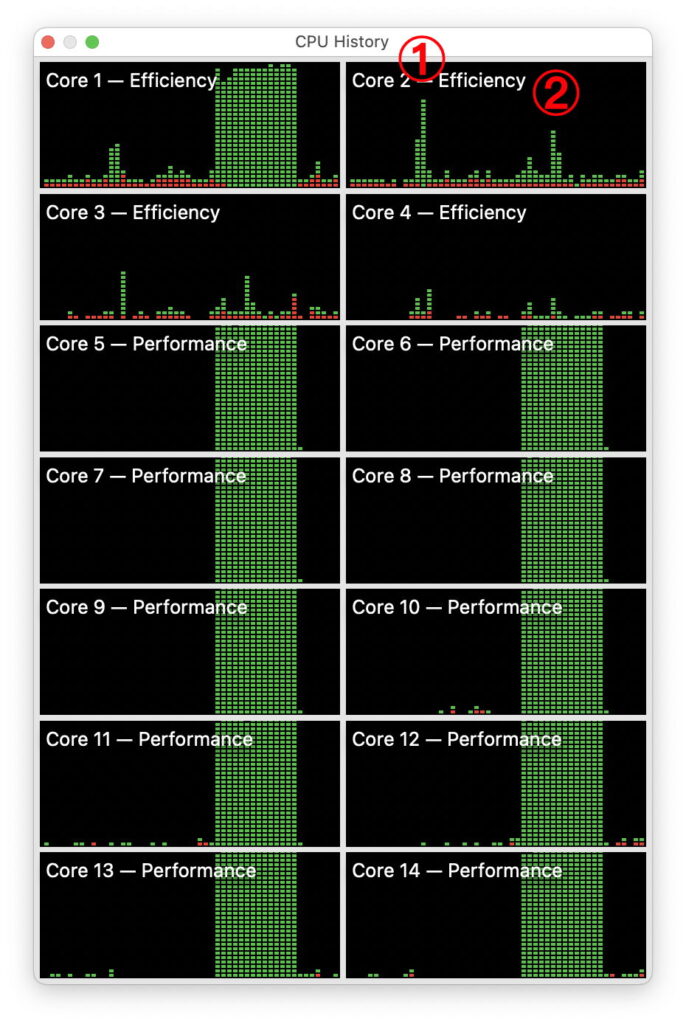
These two tests are shown in the CPU History window from Activity Monitor. The single NEON thread run alone in the E cluster is marked by 1, when there was essentially no activity in the P cores. The figure 2 marks when the same NEON thread was run while all 10 P cores and one of the E cores were running the floating point maths. Yet the NEON thread at 2 completed in less than half the time of that at 1.
With just two substantial threads running on the E cluster, there’s just as much processing power as when there was just the one floating point thread. So the 11 floating point threads complete in the same time, regardless of whether the NEON thread is also running. Therefore this extra performance comes free, with nothing else being slowed to compensate.
Of course in the real world, this sort of effect is likely to be extremely rare. But it might account for the occasional unexpectedly good performance of a background thread running at low QoS, and I can’t see any downsides either.
The other way you could get that low QoS thread to perform far better would be running it in a Virtual Machine, as that runs everything on P cores regardless of their QoS. Sadly, despite searching extensively, I still haven’t discovered any other way of convincing macOS to run low QoS threads any faster, except by magic.




{kind=link}