Comparing in-core performance of Intel, M3 and M4 CPU cores
It has been a long time since I last compared performance between CPU cores in Intel and Apple silicon Macs. This article compares six in-core measures of CPU performance across four different models, two with Intel processors, an M3 Pro, and an M4 Pro.
If you’re interested in comparing performance across mixed code modelling that in common apps, then look no further than Geekbench. The purpose of my tests isn’t to replicate those, but to gain insight into the CPU cores themselves, when running tight number-crunching loops largely using their registers and accessing memory as little as possible. This set of tests lays emphasis on those run at low Quality of Service (QoS), thus on the E cores of Apple silicon chips. Although those run relatively little user code, they are responsible for much of the background processing performed by macOS, and can run threads at high QoS when there are no free P cores available, although they do that at higher frequencies to deliver better performance.
Methods
Testing was performed on four Macs:
iMac Pro 2017, 3.2 GHz 8-core Intel Xeon W, 32 GB memory, Sequoia 15.3.2;
MacBook Pro 16-inch 2019, 2.3 GHz 8-core Intel Core i9, 16 GB memory, Sequoia 15.5;
MacBook Pro 16-inch 2023, M3 Pro, 36 GB memory, Sequoia 15.5;
Mac mini 2024, M4 Pro, 48 GB memory, Sequoia 15.5.
Six test subroutines were used in a GUI harness, as described in many of my previous articles. Normally, those include tests I have coded in Arm Assembly language, but for cross-platform comparisons I rely on the following coded in Swift:
float mmul, direct calculation of 16 x 16 matrix multiplication using nested for loops on Floats.
integer dot product, direct calculation of vector dot product on vectors of 4 Ints.
simd_float4 calculation of the dot-product using simd_dot in the Accelerate library.
vDSP_mmul, a function from the vDSP sub-library in Accelerate, multiplies two 16 x 16 32-bit floating point matrices, which in M1 and M3 chips appears to use the AMX co-processor;
SparseMultiply, a function from Accelerate’s Sparse Solvers, multiplies a sparse and a dense matrix, and may use the AMX co-processor in M1 and M3 chips.
BNNSMatMul matrix multiplication of 32-bit floating-point numbers, here in the Accelerate library, and since deprecated.
Source code for the last four is given in the appendix to this article.
Each test was run first in a single thread, then in four threads simultaneously. Loop throughput per second was calculated from the average time taken for each of the four threads to complete, and compared against the single thread to ensure it was representative. Results are expressed as percentages compared to test throughput at high QoS on the iMac Pro set at 100%. Thus a test result reported here as 200% indicates the cores being tested completed calculations in loops at twice the rate of those in the cores of the iMac Pro, so are ‘twice the speed’.
High QoS
User threads are normally run at high QoS, so getting the best performance available from the CPU cores. In Apple silicon chips, those threads are run preferentially on P cores at high frequency, although that may not be at the core’s maximum. Results are charted below.
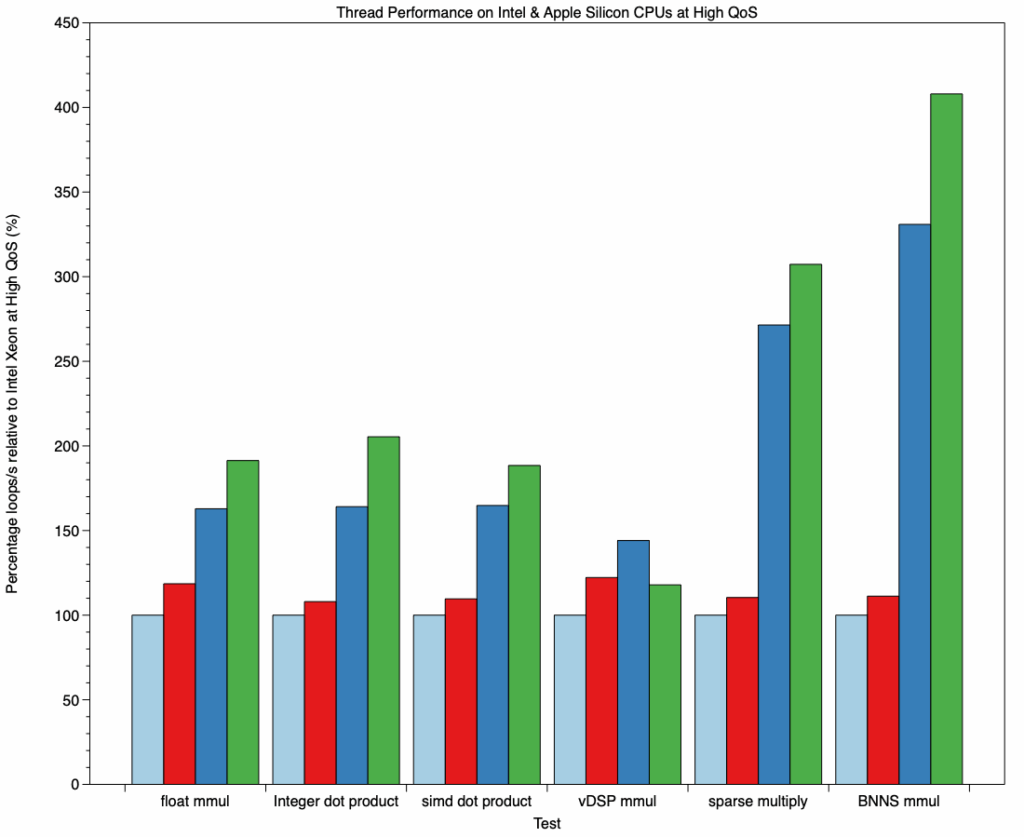
Each cluster of bars here shows loop throughput for one test relative to the iMac Pro’s 3.2 GHz 8-core Xeon processor at 100%. Pale blue and red bars are for the two Intel Macs, the M3 Pro is dark blue, and the M4 Pro green. The first three tests demonstrate what was expected, with an increase in performance in the M3 Pro, and even more in the M4 Pro to reach about 200%.
Results from vDSP matrix multiplication are different, with less of an increase in the M3 Pro, and a reduction in the M4 Pro. This may reflect issues in the code used in the Accelerate library. That contrasts with the huge increases in performance seen in the last two tests, rising to a peak of over 400% in BNNS matrix multiplication.
With that single exception, P cores in recent Apple silicon chips are out-performing Intel CPU cores by wider margins than can be accounted for in terms of frequency alone.
Low QoS
When expressed relative to loop throughput at high QoS, no clear trend emerges in Apple silicon chips. This reflects the differences in handling of threads run at low QoS: as the Intel CPUs used in Macs only have a single core type, they can only run low QoS threads at lower priority on the same cores. In Apple silicon chips, low QoS threads are run exclusively on E cores running at frequencies substantially lower than their maximum, for energy efficiency. This is reflected in the chart below.
In the Intel Xeon W of the iMac Pro, low QoS threads are run at a fairly uniform throughput of about 45% that of high QoS threads, and in the Intel Core i9 that percentage is even lower, at around 35%. Throughput in Apple silicon E cores is more variable, and in the case of the last test, the E cores in the M4 Pro reach 66% of the throughput of the Intel Xeon at high QoS. Thus, Apple appears to have chosen the frequencies used to run low QoS threads in the E cores to deliver the required economy rather than a set level of performance.
Conclusions
CPU P core performance in M3 and M4 chips is generally far superior to CPUs in late Intel Macs.
Performance in M3 P cores is typically 160% that of a Xeon or i9 core, rising to 330%.
Performance in M4 P cores is typically 190% that of a Xeon or i9 core, rising to 400%.
Performance in E cores when running low QoS threads is more variable, and typically around 30% that of a Xeon or i9 core at high QoS, to achieve superior economy in energy use.
On Intel processors running macOS Sequoia, low QoS threads are run significantly slower than high QoS threads, at about 45% (Xeon) or 30-35% (i9).
My apologies for omitting legends from the first version of the two charts, and thanks to @holabotaz for drawing my attention to that error, now corrected.




{kind=link}
{kind=link}