Apple silicon: 4 A little help from friends and co-processors
So far in this series, I have looked in broad terms at how the CPU cores in Apple silicon chips work, and how they use frequency control and two types of core to deliver high performance with low power and energy use. As I hinted previously, their design also relies on specialist processing units and co-processors, the subject of this article.
Apple’s Arm CPU cores already pull a lot of tricks to achieve high performance. Among those are prediction of which instructions are to be executed next, and to execute instructions out of order when possible. The former keeps their execution pipeline flowing as efficiently as possible without it waiting for decisions to be made about branches in the code; the latter can eliminate wasted time when the next instructions would require the core to wait before it can continue execution in strict order. Together, and with other techniques, they can only ensure that computational units in each core work as efficiently as possible.
Specialist processing units, here the NEON vector processor in each CPU core, and co-processors like the neural engine (ANE), achieve what can be huge performance gains by processing multiple data simultaneously, in a SIMD (single instruction, multiple data) architecture.
NEON vector processor
The simplest of these to understand is this vector processing unit within each CPU core, that can accelerate operations by factors of 2-8 times.
In the floating-point unit in a core, multiplying two 32-bit numbers is a single instruction. When you need to multiply a thousand or a million pairs of numbers, then a thousand or million instructions have to be executed to complete that task. In the NEON unit in an Arm core, instead of loading each register with a single 32-bit number for that multiplication, the unit has wide registers of 128 bits that are packed with four 32-bit numbers, and it then multiplies them four at a time. Thus a NEON vector processor can multiply and do much else on 32-bit floating point numbers at four times the speed of a normal floating-point unit.
The NEON unit is the odd man out among these specialist processing units, as it’s built into each of the CPU cores, both P and E, and executes instructions from the standard Arm instruction set. This makes it theoretically accessible to anyone writing code for Apple silicon chips, although it’s not quite as simple as that might sound. Current compilers for languages such as Swift and Objective-C don’t provide that access, so in practice unless a developer is prepared to write their own assembly code, the NEON unit is only accessible through mathematical libraries, including the vast Accelerate library provided by Apple.
While you might have suspected that the NEON unit in an E core would be a pale shadow of that in a P core, that’s not the case, and in the M3 chip the NEON unit in an E core processes at around 70% of the speed of that in a P core, and is slightly faster than the P core in an M1.
Neural engine
The Apple Neural Engine (ANE) is a separate unit in M-series chips, and isn’t directly accessible to third parties. As a result, knowledge of it is limited, and has been summarised by Matthijs Hollemans in this GitHub document.
Access to ANE computation is only available through CoreML and related features in macOS. Even there, developers are given limited options as to what does get executed in the ANE, and in practice it appears little used even when running Machine Learning tasks. The command tool powermetrics does report ANE power use separately, but if that’s reliable even tests intended to exercise it appear to be run relatively little on the ANE itself.
Apple Matrix Co-Processor (AMX)
This was first introduced in the iPhone 11, but Apple has never acknowledged its existence nor has it provided any information about the AMX. The best summary of work to date is given in a recent preprint by Filho, Brandão and López.
In M-series chips, each cluster of CPU cores, whether P or E in type, has its own AMX, which shares the L2 cache used by that cluster, and has access to Unified memory. Its instructions are passed to it from CPU cores, as they’re encoded as Arm instructions using special reserved codes, and data is passed via memory and not directly between CPU cores and the AMX. Performance is optimised for working with matrices, rather than the vectors preferred by NEON units, and Filho and his colleagues have demonstrated some extremely high performance in demanding tests.
Access to AMX co-processors is strictly controlled; although Filho and a few others have been able to run their own code on the AMX, more generally the only way that a developer can use the power of the AMX is via Apple’s Accelerate library. powermetrics doesn’t report AMX power use separately, but it’s assumed to be included in that for the CPU cores.
In some M1 variants, macOS core allocation strategy appears to be modified to take into account AMX use. As each CPU core cluster has its own AMX, when running multiple threads presumed to make use of those co-processors, they’re allocated to balance the thread numbers across clusters. Instead of high QoS threads being allocated to the first P cluster, then the second, and finally to the E cluster, as thread number increases, a different pattern is seen.
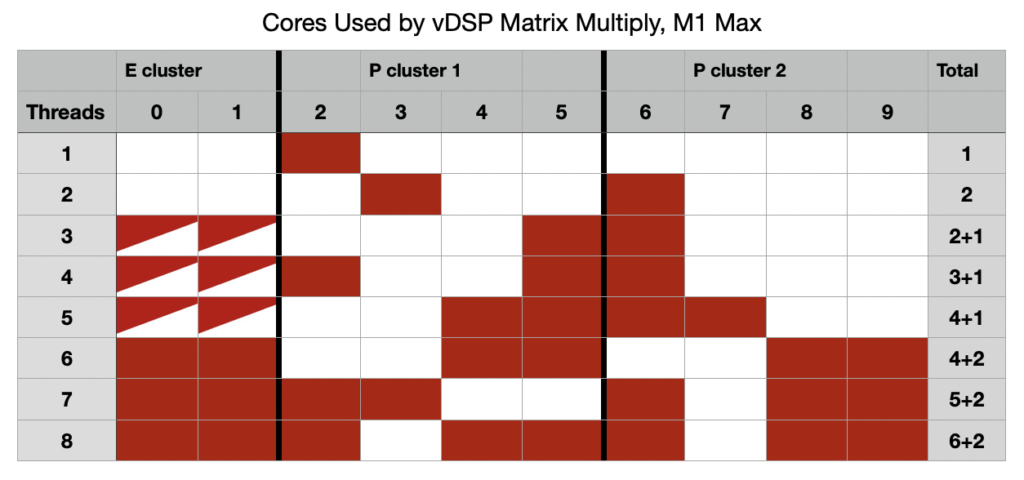
Red-filled cells here show the cores used when running matrix multiplication threads at high QoS, for different numbers of threads. Normally, when 2 threads are run, they’re allocated to P cores in the same cluster, likewise with 3 and 4 threads. Instead, the second thread is allocated to a core in the second P cluster, and with 3 threads the third is run by the two E cores, which also share their own AMX. This balancing of threads across the three clusters continues until 8 threads are running with just one P core left idling in each of the two P clusters.
This distinctive pattern of core allocation isn’t seen when the same tests are performed on an M3 Pro, with its single P and E clusters.
GPU
Although primarily intended for accelerating graphics, M-series Graphics Processing Units (GPUs) can be used in Compute mode to perform general-purpose computation, as in most other GPUs. This is the only specialist processing unit that offers developers relatively free access, although even here it comes in the form of Metal Shading Language code, based on the C++ language, in a Metal Shader. Setting this up is elaborate, requires compilation of the Shader at some stage, and management of data and command buffers.
Members of an M-series family of chips have different GPUs, with Max and Ultra variants having the greatest computational capacity in their large GPUs, while the basic variant has the smallest GPU. Where apps use this Compute feature, it can dramatically improve performance, although this appears to be relatively unusual. Fortunately, as powermetrics reports measurements separately for the GPU, including power use, this is straightforward to assess.
Power use
The great advantage of co-processors is that, when they’re not being used, they use little or no power at all. However, when running at full load, their power use may well exceed the total of all the CPU cores.
Maximum power used by the 12 cores in an M3 Pro is typically less than 7 W when using its integer or floating-point units; that rises to over 13 W when running code in its NEON vector processor units. Although power use can’t be measured separately for the AMX, when it’s presumed to be under heavy load, the total used by that and CPU cores rises to 45 W.
GPU power consumption inevitably varies greatly according to the GPU. A heavy Compute workload running on the modest 18-core GPU in an M3 Pro can readily draw 24 W, and the 40 GPU cores in an M3 Max could exceed 40 W.
Unfortunately, comparing energy use across identical tasks run on CPU cores and co-processors is fraught with difficulty, but in many circumstances using CPU cores wouldn’t be feasible anyway. Perhaps the most useful comparison here is with a warship equipped with diesel engines for normal cruising at 10-15 knots, and gas turbines to accelerate it quickly up to speeds of over 30 knots when required.
Concepts
Both P and E cores contain their own NEON vector processing unit that can apply single instructions to multiple data to achieve large improvements in performance for suitable tasks.
The neural engine, ANE, can be accessed indirectly through macOS libraries, but appears little-used at present.
Each CPU core cluster shares its own AMX matrix co-processor, which can achieve very high performance, but can only be accessed through certain functions in Apple’s Accelerate maths library.
Developers can write Metal Shaders to use the GPU in Compute mode. Its performance depends on the variant of M-series chip, but can deliver great improvement for certain tasks.
Co-processors use little or no power when not in use, but high power when fully loaded. Thus they are part of the efficient design of Apple silicon chips, offering great performance when needed.
Previously in this series
Apple silicon: 1 Cores, clusters and performance
Apple silicon: 2 Power and thermal glory
Apple silicon: 3 But does it save energy?
Further reading
Evaluating M3 Pro CPU cores: 1 General performance
Evaluating M3 Pro CPU cores: 2 Power and energy
Evaluating M3 Pro CPU cores: 3 Special CPU modes
Evaluating M3 Pro CPU cores: 4 Vector processing in NEON
Evaluating M3 Pro CPU cores: 5 Quest for the AMX
Evaluating the M3 Pro: Summary
Finding and evaluating AMX co-processors in Apple silicon chips
Comparing Accelerate performance on Apple silicon and Intel cores
M3 CPU cores have become more versatile



